

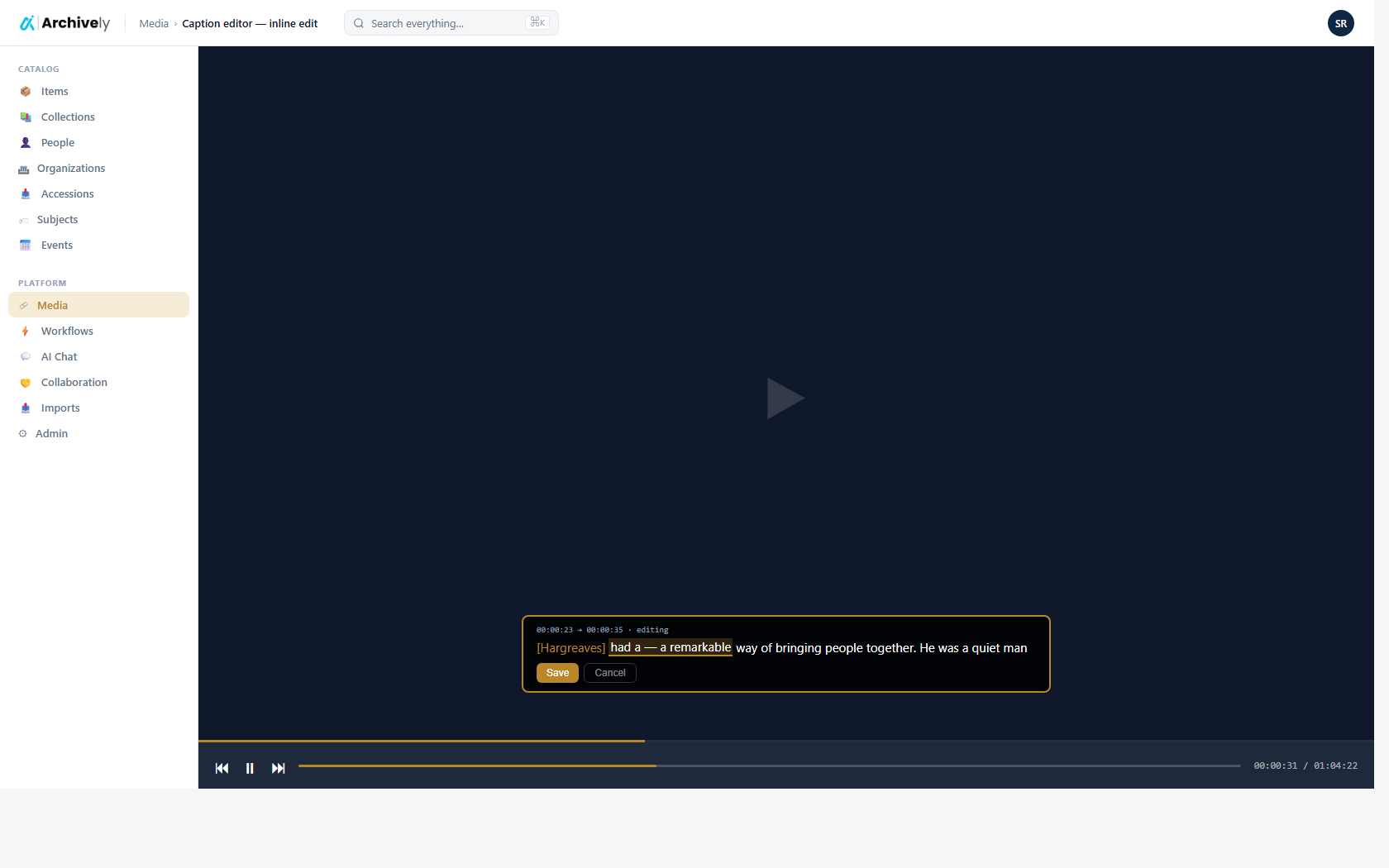

The problem
Your archive is spread across a spreadsheet, a scanner, a transcription service, and whatever publishes the finding aid.
One platform, not a stack
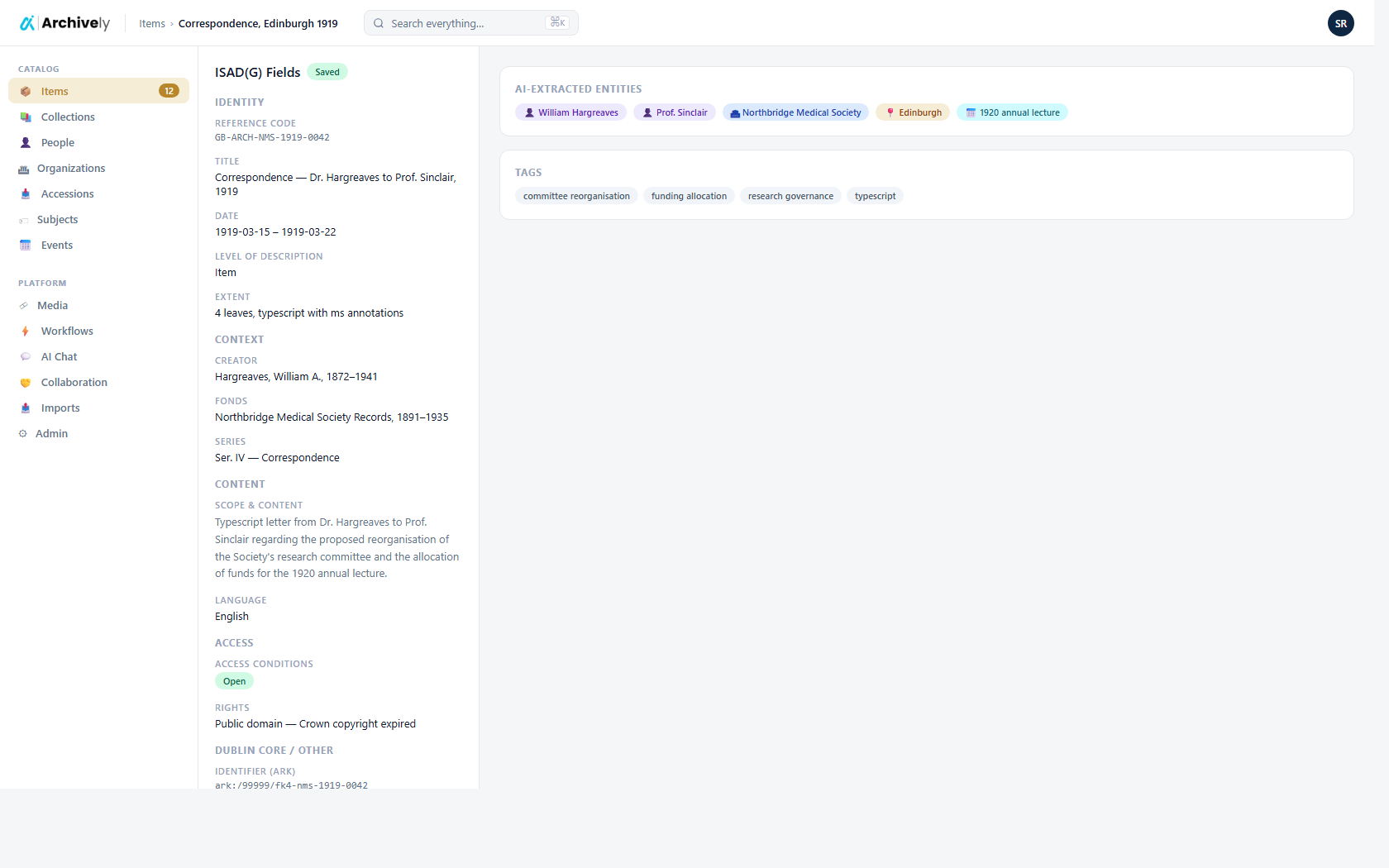
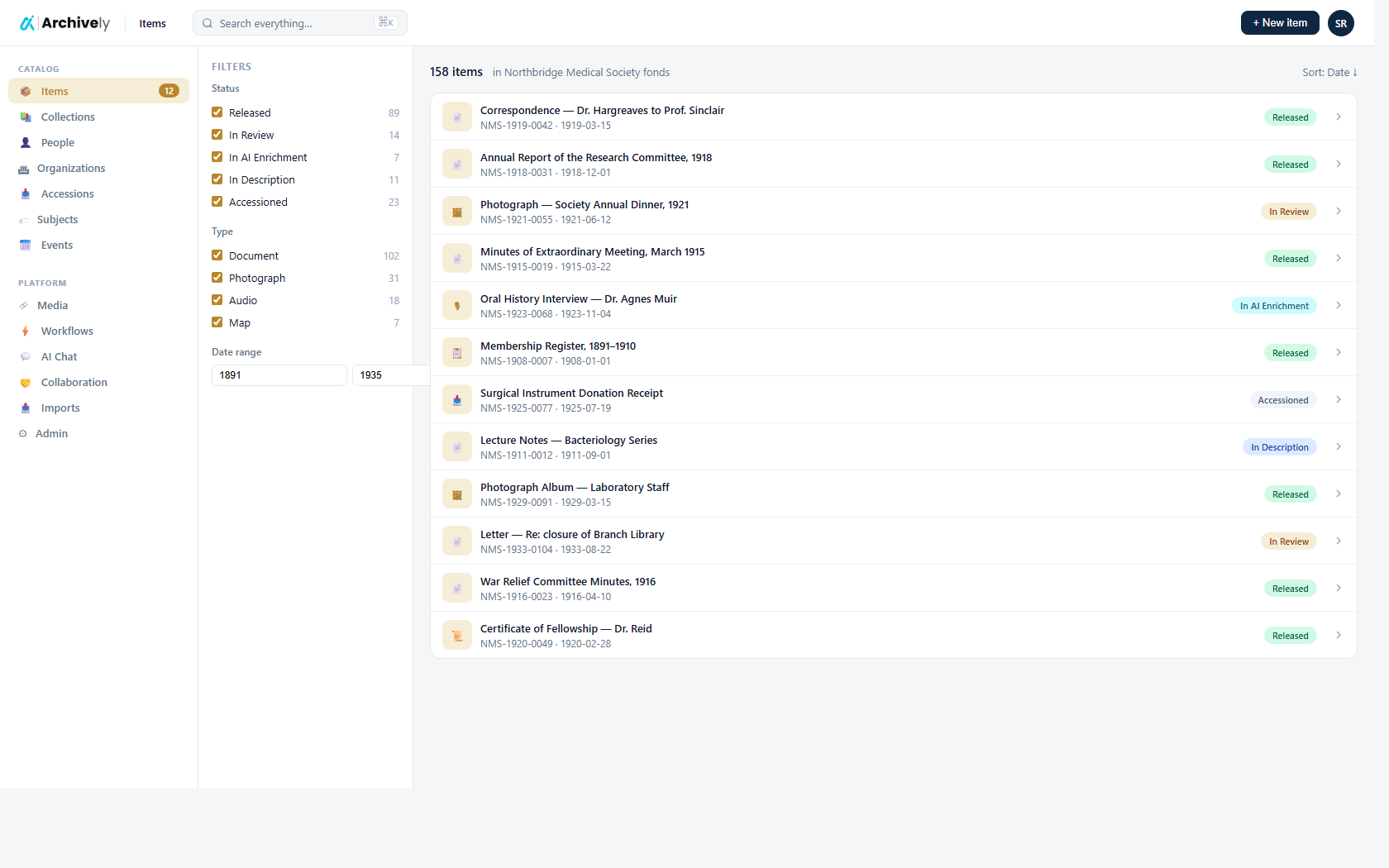
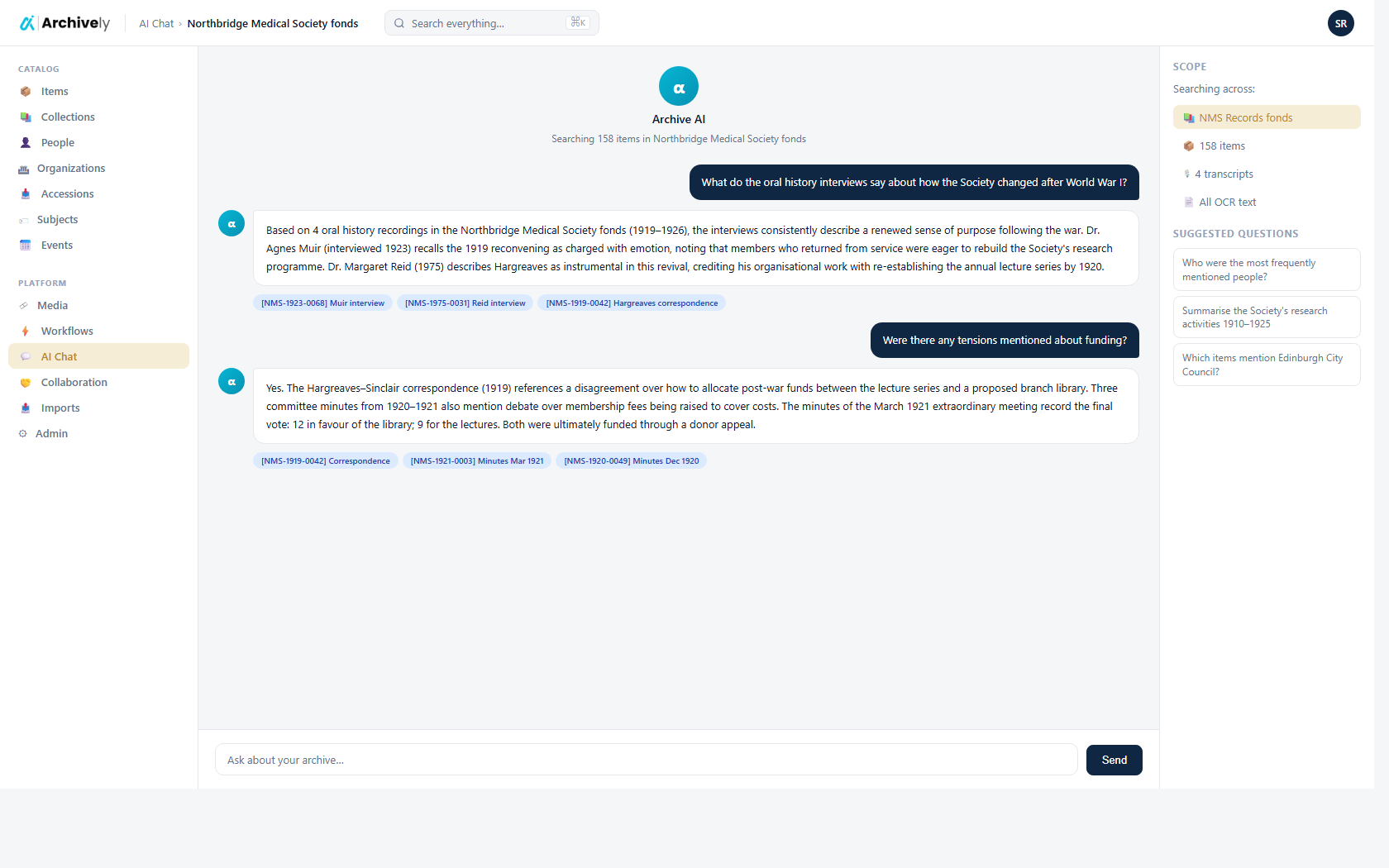
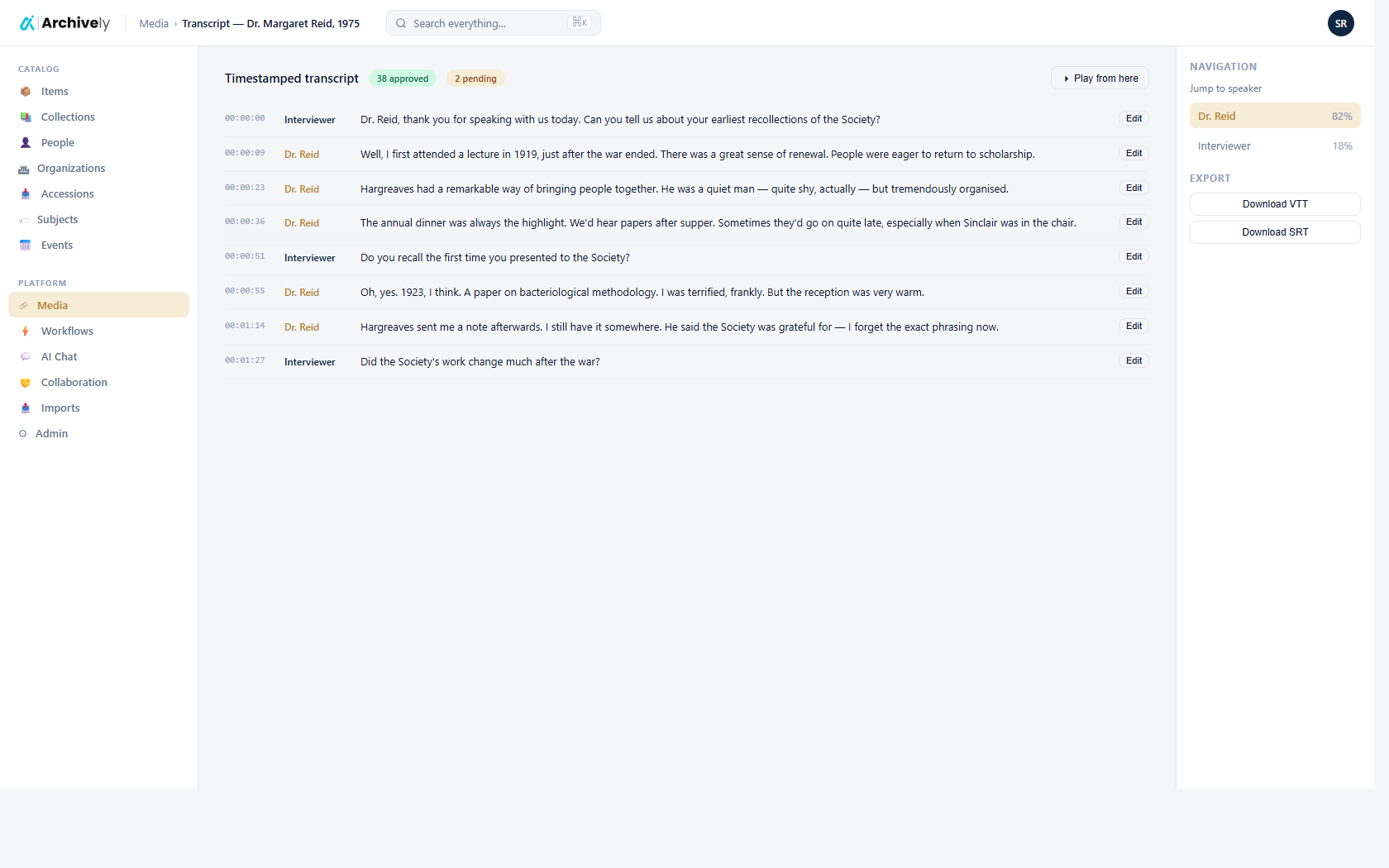
Upload, OCR, transcription, cataloging, image work, and a public portal live in one place — one data model, one login, one audit trail from intake to publication.